前言
在數據庫中,索引失效會導致查詢無法利用索引來加速,從而降低查詢性能。
今天就來探索為什么隱式類型轉換,會導致索引失效呢,為什么不能對參數進行類型轉換再匹配呢,這樣不就能用上索引呢?
隱式類型轉換之謎??
為什隱式轉換會導致索引失效
先看一個例子: create_by 的字段類型為 varchar
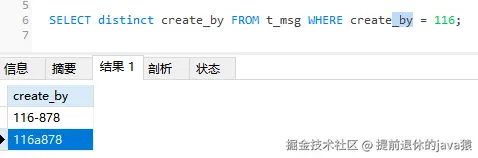
看到這兒可能很多人都會大吃一驚!
MySQL 會嘗試將 VARCHAR 類型的 create_by 字段值轉換為數字類型,然后再與 116 進行比較。在轉換過程中,MySQL 會從字符串的開頭開始解析數字,直到遇到非數字字符為止。如果字符串開頭沒有有效的數字,那么轉換結果為 0
上面的SQL 和 下面這個SQL 執行邏輯應該是相似的
SELECT distinct create_by FROM t_message WHERE CONVERT(create_by, SIGNED) = 116;
換成這個SQL我想大家都明白了,為什么索引會失效了,隱式轉換的時候如果是對列轉,那么索引就一定失效
隱式轉換索引一定失效么?轉換一定是轉列么?
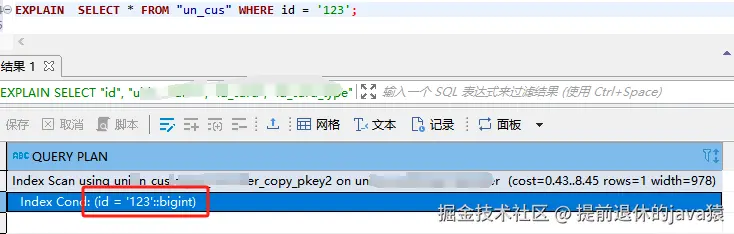
當然不是??,請看下面ID是bigint,并且執行執行計劃是 使用了主鍵索引的

再來看一張人大金倉的explain, 它這個就很清楚了,是把參數轉換成 數據庫列的類型,這樣就肯定走索引呢 : id = '123' ::bigint 如下
隱式轉換有什么規則呢?什么時候轉參數,什么時候轉列
??其實Mysql轉換是有一套優先級的: 數字類型 > 時間類型 > 字符串類型,低級向高級轉換。
??所以如果列類型的優先級高于參數類型的優先級 那么就會對參數進行類型轉換,這時候類型轉換不會對性能有啥影響。反之會去對列數據進行轉換,性能的影響就比較大
最近工作也遇到很多 數字 和 boolean 類型的轉換,在人大金倉中是 將boolean類型轉為數字,mysql 沒做測試,應該也是一樣。
為什么不能直接對參數轉換了,這樣就不會導致索引失效了?
MySQL在處理類型不匹配的比較時,通常選擇轉換列值而非參數值,從而導致索引失效。這個設計決策背后主要是按照
?MySQL遵循SQL標準中"操作數類型提升"的規則,通常會將低優先級類型轉換為高優先級類型,數值類型優先級 > 時間類型 > 字符串類型
這種轉換方向是數據庫引擎的通用設計模式
為什么SQL標準"操作數類型提升" 要這樣設計呢
?下面看看DeepSeek 是怎么回答的?
1. 語義一致性(避免歧義)與可預測性
SQL 標準要求表達式的結果類型必須明確且可預測。當操作數類型不同時,通過固定的優先級規則(如數值 > 時間 > 字符串)進行隱式轉換,確保所有數據庫實現的行為一致。例如:
數值與字符串比較時,字符串轉為數值,避免因字符編碼差異導致不確定結果。 假設 一個條件是 var_colum = 123, 如果轉換成 var_colum = '123' ,那么 ' 123 ' 這種有空格的就無法查詢了。這就是語義一致性問題。
2. 計算效率優化
高優先級類型(如數值)通常具有更高效的比較和計算機制。例如:
數值比較直接使用CPU指令,而字符串比較需逐字符處理。優先轉為數值可提升性能。
3. 索引結構的限制
我也沒咋看懂??: 索引(如B-tree)按列的原生類型組織。若強制轉換參數而非列值,存儲引擎仍需按列類型重新轉換參數,反而增加開銷。例如:
WHERE varchar_col = 123 若轉為 varchar_col = '123',仍需將字符串'123'轉回數值與索引比較,無法避免轉換。
總結
本篇文章,分析了查詢隱式轉換什么時候會索引失效,以及轉換規則優先級,以及為什么SQL標準要這么去定義,DeepSeek 給的答案是主要就是 避免歧義,提升性能。
推薦閱讀:dev.mysql.com/doc/refman/…?
知識擴展
下面第一、二點就是我們今天探索的失效場景
- 類型不匹配 如果查詢條件中的數據類型與索引列的數據類型不一致,數據庫可能會進行隱式類型轉換,破壞索引的有序性,造成索引失效。
SELECT * FROM users WHERE id = 123;
- 索引列上使用函數或表達式 當在索引列上使用函數、表達式時,數據庫無法直接使用索引的有序結構來快速定位數據,通常會導致索引失效。
SELECT * FROM users WHERE UPPER(name) = 'JOHN';
- 范圍查詢右側列 對于復合索引(多列索引),如果在復合索引的前導列使用范圍查詢,后續列的索引會失效。
SELECT * FROM table_name WHERE col1 > 10 AND col2 = 20;
- 模糊查詢以通配符開頭 在使用
LIKE 進行模糊查詢時,如果通配符 % 出現在字符串的開頭,數據庫無法利用索引的有序性進行快速匹配,會導致索引失效。
SELECT * FROM users WHERE name LIKE '%john';
5. OR 連接條件 當查詢條件使用 OR 連接多個條件,且這些條件部分沒有索引或者不全使用同一個索引時,可能會導致索引失效。
SELECT * FROM users WHERE id = 1 OR name = 'john';
6. IS NULL 和 IS NOT NULL 在某些情況下,對索引列使用 IS NULL 或 IS NOT NULL 可能會導致索引失效,尤其是在數據分布不均勻時。
SELECT * FROM users WHERE email IS NULL;
全表掃描更快 當數據庫的查詢優化器認為全表掃描比使用索引掃描更快時,會選擇全表掃描,此時索引就不會被使用。例如,當查詢的數據量占總數據量的比例較大時,優化器可能會做出這樣的決策。
索引統計信息不準確 如果索引的統計信息不準確,查詢優化器可能會做出錯誤的決策,導致索引失效。例如,表數據發生了大量的插入、刪除、更新操作,但沒有及時更新索引統計信息。
強制索引失效 在 SQL 語句中使用 IGNORE INDEX 關鍵字可以強制數據庫不使用指定的索引。
轉自https://juejin.cn/post/7490856819003785252
該文章在 2025/4/15 15:07:35 編輯過






 400 186 1886
400 186 1886


