C++代碼改造為UTF-8編碼問題的總結(jié)
當(dāng)前位置:點(diǎn)晴教程→知識(shí)管理交流
→『 技術(shù)文檔交流 』
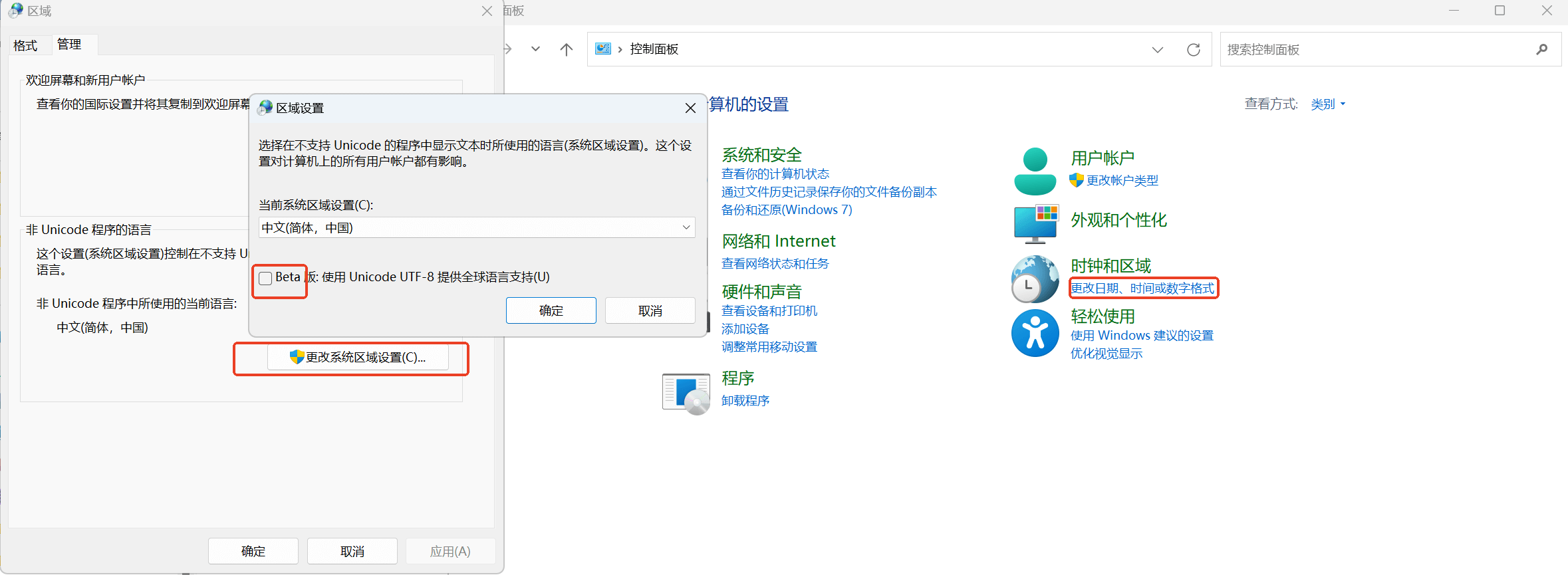
1. 引言無論是哪個(gè)平臺(tái)哪種編程語言,字符串亂碼真是一個(gè)讓人無語的問題:你說這個(gè)問題比較小吧,但是關(guān)鍵時(shí)刻來一下真是受不了。解決方式也有很多種,但是與其將編碼轉(zhuǎn)換來轉(zhuǎn)換去,不如統(tǒng)一使用同一種編碼方式,比如國(guó)際通用的UTF-8編碼。因此,新的程序代碼最好都統(tǒng)一使用UTF-8編碼的方式。但是C++作為一種歷史悠久的編程語言,肯定存在很多存量代碼,如何將其改造成UTF-8編碼也是一個(gè)問題,筆者在這里總結(jié)一二,可能不是很全,如果有遺漏就再開一篇補(bǔ)充。 2. 詳述2.1 操作系統(tǒng)統(tǒng)一使用統(tǒng)一使用UTF-8編碼還有個(gè)好處是跨平臺(tái)。但是操作系統(tǒng)本身也是有字符編碼的,這會(huì)影響到與操作系統(tǒng)相關(guān)的應(yīng)用,比如說終端。Linux系統(tǒng)一般不用擔(dān)心,目前一般都默認(rèn)使用UTF-8編碼。Windows系統(tǒng)則有點(diǎn)麻煩,一般使用ANSI碼(本地碼)。本地碼的意思就是基于當(dāng)前系統(tǒng)區(qū)域設(shè)置的字符編碼,以國(guó)內(nèi)大陸的來說就是國(guó)標(biāo)碼:GB2312/GBK/GB18030。這就是為什么Windows的終端總是出現(xiàn)亂碼的原因,因?yàn)榫幋a不一致:GBK編碼的終端遇到UTF-8編碼字符串當(dāng)然不會(huì)正確展示了。 當(dāng)然現(xiàn)在Windows系統(tǒng)也能設(shè)置成UTF-8編碼了,如下圖1所示。但是還是建議不要輕易這么設(shè)置,Windows系統(tǒng)沒有將UTF-8編碼設(shè)置系統(tǒng)的默認(rèn)編碼主要也是為了保證兼容性,在Unicode編碼大規(guī)模使用之前本地碼還是使用了相當(dāng)長(zhǎng)的時(shí)間的,有相當(dāng)數(shù)據(jù)量的遺留程序都是使用的本地碼。為了避免大規(guī)模應(yīng)用程序亂碼問題的出現(xiàn),不能要求每個(gè)用戶都這么設(shè)置。
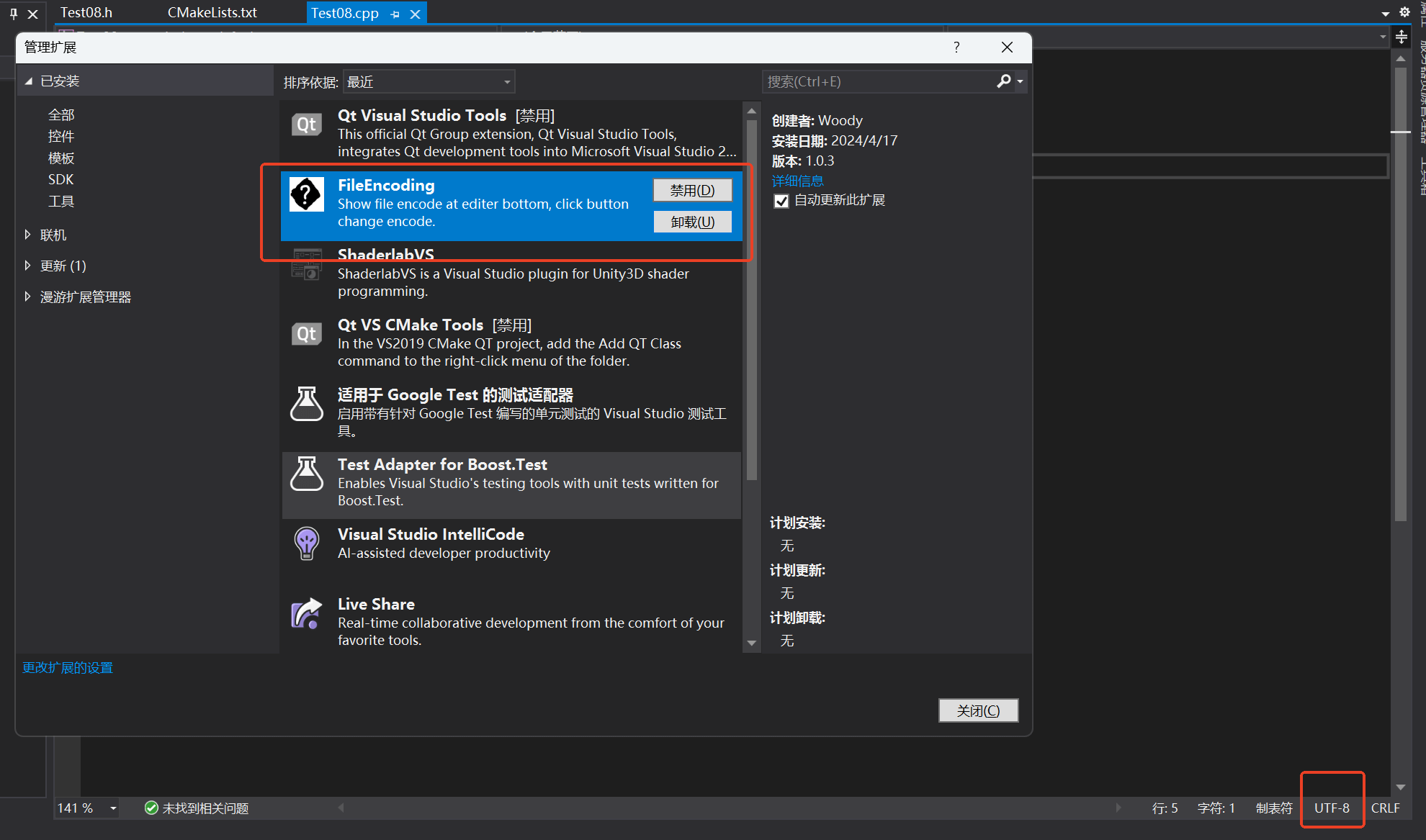
2.2 編譯器雖然最好不要在操作系統(tǒng)層面設(shè)置成UTF-8編碼,但是還是可以編寫基于UTF-8編碼的程序的。將代碼文件修改成UTF-8編碼是一方面,另外一方面是編譯器要將代碼文件按照UTF-8編碼進(jìn)行編譯。因?yàn)闊o論是ASCII、GB18030還是UTF-8編碼的文本文件,其實(shí)都是沒有具體的標(biāo)識(shí)符的,編譯器需要知道以哪種字符編碼來編譯代碼文件中的字符。 Linux系統(tǒng)還是不用擔(dān)心,默認(rèn)情況下文本文件通常使用UTF-8編碼,GCC編譯器也會(huì)默認(rèn)使用系統(tǒng)的默認(rèn)字符編碼也就是UTF-8編碼來進(jìn)行編譯。麻煩的還是Windows系統(tǒng),暫時(shí)不討論各種復(fù)雜的情況,筆者以Visual Studio的MSVC編譯器為例,介紹一下自己的做法。 首先還是要將代碼文件修改成UTF-8編碼,這里推薦使用Visual Studio的一個(gè)擴(kuò)展:FileEncoding,它可以很方便的在代碼頁面的右下角修改代碼文件編碼,如下圖2所示。不過有一點(diǎn)要注意,選擇使用UTF-8編碼而不是UTF-8(BOM)編碼。
然后是給MSVC編譯器增加一個(gè)編譯選項(xiàng):/utf-8,這個(gè)編譯選項(xiàng)會(huì)將源代碼字符集和執(zhí)行字符集指定為使用UTF-8編碼字符集。具體來說,如果你是原生的MSVC的項(xiàng)目,應(yīng)該執(zhí)行的操作是:
如果是CMake項(xiàng)目,那么在CMakeLists.txt中增加如下配置,意思是如果是MSVC編譯器,就增加/utf-8選項(xiàng): 最后,還需要考慮一點(diǎn),字符最終需要顯示到終端的,無論是GUI終端還是命令行終端,你必須確保終端的字符編碼也是UTF-8編碼才行。例如打印字符串到命令行終端,可使用如下示例代碼(C++17環(huán)境下): 這段代碼的意思是在Windows環(huán)境下,設(shè)置控制臺(tái)輸出窗口的代碼頁是65001,也就是UTF-8編碼。同時(shí)由于代碼文件是UTF-8編碼,字符串常量 2.3 漸進(jìn)升級(jí)按照以上步驟編寫新的基于UTF-8編碼的程序是沒有問題的,但是實(shí)際操作大概率不行。因?yàn)镃++程序往往有足夠多的存量代碼,我們往往需要以庫的形式或者組件的形式來調(diào)用它們。問題是C++程序調(diào)用庫是需要include頭文件的,一旦設(shè)置了/utf-8編譯選項(xiàng),MSVC就會(huì)強(qiáng)制將這些舊代碼按照UTF-8編碼進(jìn)行編譯。在這種情況下,有很大的概率會(huì)出現(xiàn)亂碼問題,或者出現(xiàn)如下編譯錯(cuò)誤: 一般而言,MSVC項(xiàng)目的存量代碼一般為本地編碼(GBK編碼),最直接的解決方案是一個(gè)一個(gè)地按照上述方式去升級(jí)這些代碼,但是這樣做就要看存量代碼有多少、是否有權(quán)限這么做了,如果工作量太大還是不建議這么做。比較合理的辦法還是漸進(jìn)式更新:
由于UTF-8編碼是兼容ASCII字符的,因此即使強(qiáng)制要求MSVC按照UTF-8編碼編譯這個(gè)文件,也是不會(huì)出現(xiàn)亂碼或者編譯不通過的問題的。并且這樣也是有可行性的,一般頭文件的代碼內(nèi)容很少,修改起來也不容易出錯(cuò)。其實(shí)在大部分情況下也確實(shí)不需要修改什么,大多數(shù)常用庫為了方便國(guó)際通用,頭文件很少出現(xiàn)非ASCII字符。 當(dāng)然這樣做也存在一個(gè)問題:舊的代碼接口是本地編碼,新的代碼卻是UTF-8編碼,調(diào)用的時(shí)候字符串傳參需要將UTF-8編碼轉(zhuǎn)換成GBK編碼字符串。但是這也是沒有辦法的辦法,只修改接口部分的代碼總比大規(guī)模修改程序好。想要完全避免字符編碼的問題就要統(tǒng)一使用UTF-8,最好按照這個(gè)原則,從調(diào)用端到底層框架逐漸將代碼都升級(jí)成UTF-8編碼。 3. 案例所有接口統(tǒng)一使用UTF-8編碼真的是任何程序開發(fā)的金玉良言,否則就總是會(huì)遇到字符編碼轉(zhuǎn)換的問題,非常影響工作效率。不過可能因?yàn)榧嫒菪曰蛘咂渌颍壳斑€做不到將所有的接口統(tǒng)一編碼。筆者這里就列舉一些常用的組件和庫的接口的字符串編碼案例。 3.1 std::filesystem::path個(gè)人認(rèn)為C++17的 在MSVC編譯器中,以L開頭的字符串是一個(gè)寬字符字符串,對(duì)應(yīng)于UTF-16編碼。而如果本身是一個(gè)UTF-8編碼的 經(jīng)過筆者的驗(yàn)證,其實(shí)Windows環(huán)境下使用GBK編碼字符串初始化 不過,雖然 3.2 Qt的QStringQt的 這是因?yàn)?code style="margin: 0px 3px; padding: 0px 5px; font-family: ui-monospace, SFMono-Regular, "SF Mono", Menlo, Consolas, "Liberation Mono", monospace, sans-serif; line-height: 1.8; display: inline-block; overflow-x: auto; vertical-align: middle; border-radius: 3px; background-color: rgb(251, 229, 225); color: rgb(192, 52, 29); border: none !important;">"這是中文字符串"使用的是UTF-8編碼,這個(gè)字符串字面量會(huì)被正確地解釋為Unicode字符。接著當(dāng)構(gòu)造 但是對(duì)于已經(jīng)存在的 這是因?yàn)?code style="margin: 0px 3px; padding: 0px 5px; font-family: ui-monospace, SFMono-Regular, "SF Mono", Menlo, Consolas, "Liberation Mono", monospace, sans-serif; line-height: 1.8; display: inline-block; overflow-x: auto; vertical-align: middle; border-radius: 3px; background-color: rgb(251, 229, 225); color: rgb(192, 52, 29); border: none !important;">QString默認(rèn)假設(shè)傳入的C風(fēng)格字符串是以ISO 8859-1(Latin-1)編碼的。 3.3 GDAL在統(tǒng)一使用UTF-8編碼之后,就不用再設(shè)置文件路徑的字符編碼不是UTF-8了,直接傳遞到GDALOpen函數(shù)中即可。 3.4 OpenCVOpenCV的讀取圖像接口cv::imread使用的應(yīng)該是本地編碼,在Windows環(huán)境下需要進(jìn)行編碼轉(zhuǎn)換: 筆者之前的博文《c++中utf8字符串和gbk字符串的轉(zhuǎn)換》中提供了Utf8編碼與GBK編碼之間的轉(zhuǎn)換。 4. 補(bǔ)充筆者查閱字符編碼相關(guān)的資料的時(shí)候,就感嘆這方面的知識(shí)還真就是一本爛賬,除非深入了解,否則是無法完全論述清楚的。個(gè)人看法是要認(rèn)清字符編碼的本質(zhì)是將有意義的字符與二進(jìn)制數(shù)據(jù)類型類型對(duì)應(yīng)起來。以國(guó)內(nèi)的情況來說,我們只需要理解三種字符編碼:ASCII、ANSI以及Unicode,它們大致分別對(duì)應(yīng)于1個(gè)字節(jié)、2個(gè)字節(jié)、以及4個(gè)字節(jié)。
5. 參考
轉(zhuǎn)自https://www.cnblogs.com/charlee44/p/18712053 該文章在 2025/2/13 10:16:42 編輯過 |
關(guān)鍵字查詢
相關(guān)文章
正在查詢... 晴ERP是一款針對(duì)中小制造業(yè)的專業(yè)生產(chǎn)管理軟件系統(tǒng),系統(tǒng)成熟度和易用性得到了國(guó)內(nèi)大量中小企業(yè)的青睞。")
晴PMS碼頭管理系統(tǒng)主要針對(duì)港口碼頭集裝箱與散貨日常運(yùn)作、調(diào)度、堆場(chǎng)、車隊(duì)、財(cái)務(wù)費(fèi)用、相關(guān)報(bào)表等業(yè)務(wù)管理,結(jié)合碼頭的業(yè)務(wù)特點(diǎn),圍繞調(diào)度、堆場(chǎng)作業(yè)而開發(fā)的。集技術(shù)的先進(jìn)性、管理的有效性于一體,是物流碼頭及其他港口類企業(yè)的高效ERP管理信息系統(tǒng)。")
晴WMS倉儲(chǔ)管理系統(tǒng)提供了貨物產(chǎn)品管理,銷售管理,采購管理,倉儲(chǔ)管理,倉庫管理,保質(zhì)期管理,貨位管理,庫位管理,生產(chǎn)管理,WMS管理系統(tǒng),標(biāo)簽打印,條形碼,二維碼管理,批號(hào)管理軟件。")
晴免費(fèi)OA是一款軟件和通用服務(wù)都免費(fèi),不限功能、不限時(shí)間、不限用戶的免費(fèi)OA協(xié)同辦公管理系統(tǒng)。")
|


 400 186 1886
400 186 1886
晴公司官網(wǎng)")