【Excel】未來5年你必須要掌握的函數(shù)之15:TEXTAFTER/TEXTBEFORE函數(shù)
當(dāng)前位置:點(diǎn)晴教程→知識(shí)管理交流
→『 技術(shù)文檔交流 』
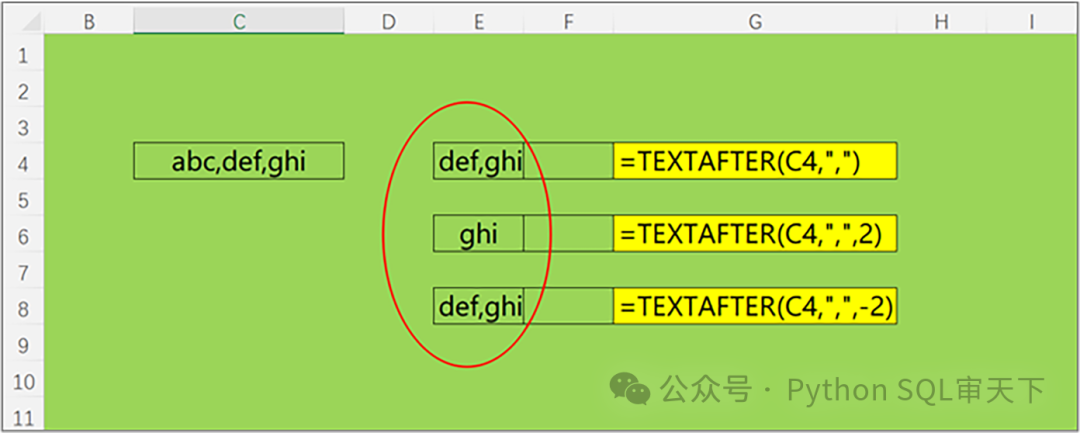
TEXTAFTER 與 TEXTBEFORE 函數(shù)是 EXCEL 新增加的一對(duì)函數(shù)。單從名稱來看,TEXTAFTER 意為特定內(nèi)容之后的文本,而 TEXTBEFORE 則表示特定內(nèi)容之前的文本,由此不難知曉這兩個(gè)函數(shù)的主要用途是從某一文本中提取部分內(nèi)容。 例如,假設(shè)有一個(gè)文本被逗號(hào)分隔成兩部分,前半部分設(shè)為 a,后半部分設(shè)為 b。在此情形下,運(yùn)用TEXTAFTER 函數(shù)便能提取出逗號(hào)之后的部分,也就是 b;而使用 TEXTBEFORE 函數(shù)則可獲取逗號(hào)之前的部分,即 a。 這兩個(gè)函數(shù)除了函數(shù)名稱存在差異以外,其參數(shù)設(shè)置沒有任何區(qū)別。 1、基本語法 ?這里我們以TEXTAFTER函數(shù)為例,來詳細(xì)說明它的參數(shù)設(shè)置情況。 text:必需參數(shù),代表要在其中提取文本的源文本字符串。 delimiter:必需參數(shù),用于指定分隔符。 instance_num:可選參數(shù),指定要返回第幾個(gè)分隔符之后的文本。默認(rèn)值為1。如果文本中有多個(gè)相同的分隔符,通過這個(gè)參數(shù)可以選擇提取哪一個(gè)分隔符之后的內(nèi)容。例如,如果文本是“蘋果,香蕉,橙子”,當(dāng)instance_num = 2時(shí),將返回“橙子”。 match_mode:可選參數(shù),0表示大小寫敏感;1表示大小寫不敏感,默認(rèn)為0。 match_end:可選參數(shù),0表示文本結(jié)束不作為分隔符;1表示文本結(jié)束作為分隔符,默認(rèn)為0。 if_not_found:可選參數(shù),當(dāng)找不到指定的分隔符時(shí)返回的值。默認(rèn)值為空文本“”。 2、基本用法 =TEXTAFTER(C4,",") 表示在單元格C4中的文本內(nèi)容中,提取第一個(gè)逗號(hào)“,”之后的所有文本。 =TEXTAFTER(C4,",",2) 表示在單元格C4中的文本內(nèi)容中,提取第二個(gè)逗號(hào)“,”之后的所有文本。 =TEXTAFTER(C4,",",-2) 表示在單元格C4的文本內(nèi)容中,提取倒數(shù)第二個(gè)逗號(hào)“,”之后的所有文本。
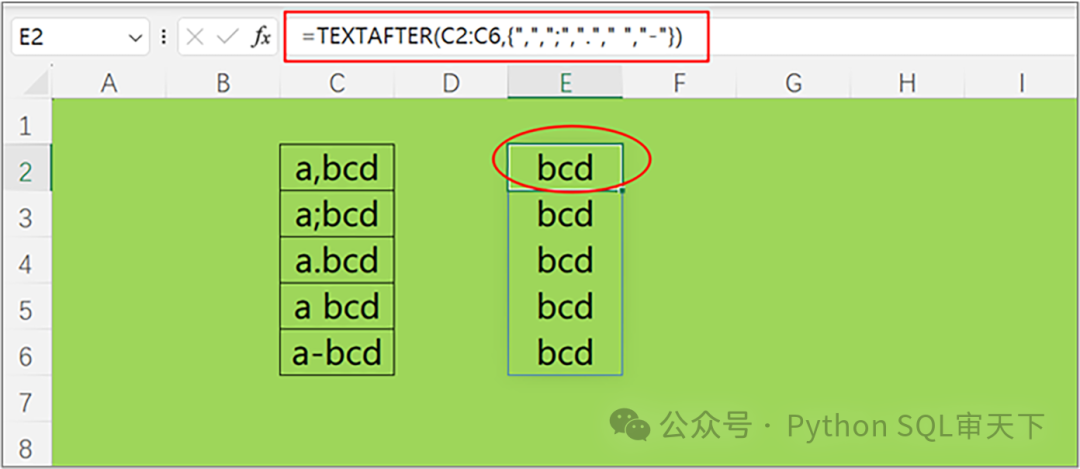
處理多個(gè)分隔符 假設(shè)存在這樣一列數(shù)據(jù),其中“a”與后續(xù)的“bcd”被分隔開來,然而所采用的分隔符種類繁多,包括逗號(hào)、分號(hào)、點(diǎn)號(hào)、空格以及橫杠等。如果針對(duì)每一種分隔符情形都編寫一個(gè) TEXTAFTER 函數(shù)來進(jìn)行拆分,那么不僅工作量會(huì)很大,而且原本可以自動(dòng)化的操作也將淪為手動(dòng)操作,效率極低。 在這種情況下,我們可以構(gòu)建一個(gè)數(shù)組,該數(shù)組既可以是常量數(shù)組,也可以是由單元格區(qū)域構(gòu)成的數(shù)組,將所有可能出現(xiàn)的分隔符納入其中。如此一來,在執(zhí)行拆分操作時(shí),函數(shù)便能自動(dòng)識(shí)別并采用所遇到的相應(yīng)分隔符進(jìn)行拆分,從而有效提升處理效率并減少人工操作的繁瑣程度。
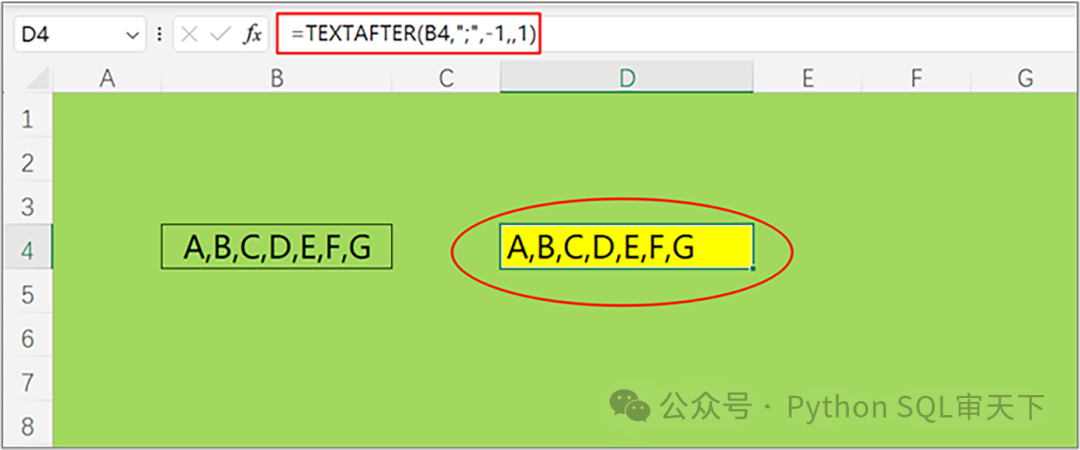
如果沒有找到就返回文本本身,這里有一個(gè)常見的寫法。 =TEXTAFTER(B4,"",-1,,1) 怎么理解上面的公式呢? 我們要在B4單元格所在的文本中去找分號(hào)后面所有的文本。而找的位置是最后一次出現(xiàn)分號(hào)的地方,也就是從右往左找的第一個(gè),找著了當(dāng)然就取出它后面的內(nèi)容,如果沒找著怎么辦呢?在這兒有一個(gè)1,這個(gè)1的意思就是表示從右往左去找,如果沒找著,那么就將end作為分隔符使用。從右往左找,end發(fā)生在字母A前面,所以一直沒找著,就將A前面的空格當(dāng)作分隔符來使用,表示找著了,那么返回它后面所有的內(nèi)容就是整個(gè)的文本。
該文章在 2024/12/3 10:47:24 編輯過 |
關(guān)鍵字查詢
相關(guān)文章
正在查詢... 晴ERP是一款針對(duì)中小制造業(yè)的專業(yè)生產(chǎn)管理軟件系統(tǒng),系統(tǒng)成熟度和易用性得到了國(guó)內(nèi)大量中小企業(yè)的青睞。")
晴PMS碼頭管理系統(tǒng)主要針對(duì)港口碼頭集裝箱與散貨日常運(yùn)作、調(diào)度、堆場(chǎng)、車隊(duì)、財(cái)務(wù)費(fèi)用、相關(guān)報(bào)表等業(yè)務(wù)管理,結(jié)合碼頭的業(yè)務(wù)特點(diǎn),圍繞調(diào)度、堆場(chǎng)作業(yè)而開發(fā)的。集技術(shù)的先進(jìn)性、管理的有效性于一體,是物流碼頭及其他港口類企業(yè)的高效ERP管理信息系統(tǒng)。")
晴WMS倉(cāng)儲(chǔ)管理系統(tǒng)提供了貨物產(chǎn)品管理,銷售管理,采購(gòu)管理,倉(cāng)儲(chǔ)管理,倉(cāng)庫(kù)管理,保質(zhì)期管理,貨位管理,庫(kù)位管理,生產(chǎn)管理,WMS管理系統(tǒng),標(biāo)簽打印,條形碼,二維碼管理,批號(hào)管理軟件。")
晴免費(fèi)OA是一款軟件和通用服務(wù)都免費(fèi),不限功能、不限時(shí)間、不限用戶的免費(fèi)OA協(xié)同辦公管理系統(tǒng)。")
|


 400 186 1886
400 186 1886
晴公司官網(wǎng)")